_(1).jpeg&blockId=0e552736-74f0-4f5a-89e1-328d4931ca7c)

해당 글을 참고해서 쓰는 글이다.


코드를 읽을 때 즉각적으로 이해할 수 있고, 코드를 수정해야할 때 어디를 수정해야하는지 바로 알 수 있다면 얼마나 좋을까?
코드가 어떻게 동작하는지 주석 하나 없이 잘 설명하는 코드를 작성하려면 어떻게 해야할까?
비디오 게임, Portal
닥터스트레인지의 포탈, 메이플스토리의 포탈처럼 ‘포탈’이라고 하면 일반적으로 다른 차원으로 가는 문이라고 생각하기 쉽다. 하지만 2007년 출시된 게임 ‘포탈’에서 포탈은 다른 차원이 아니라 방 내부에 열려있는 다른 포탈과 연결된 문이다.

포탈 제작자들은 일반적인 ‘포탈’을 생각하는 유저들에게 자신들의 포탈을 설명하기 위해 일일이 설명하지 않았다. 대신 포탈 내부에 주인공 캐릭터가 있는 방이 보이게 함으로써 포탈은 내부 방으로 연결되는 또 하나의 문을 여는 것임을 인지시켰다.
제작자들은 자신들의 포탈이 ‘다른 차원’이 아닌 같은 차원으로 이동하는 포탈임을 인지시키기 위해, 포탈을 적절한 위치에 배치했을 뿐이었다.
직관적인 프로그래밍의 3가지 방법
Choose Good Names
‘가독성있는 코드의 기술’의 저자 더스틴 보스웰과 트레버 파우처는 “이름에 정보를 담아야 한다”며 구체적이고 의미를 전달할 수 있는 이름을 선택하기 위해 최선을 다해야 한다고 말한다.
예를 들어 getData()라는 함수는 많은 정보를 담고 있지 않다. 사실, 이 함수는 대답보다 더 많은 질문을 불러일으킨다. 정확히 이 데이터가 무엇이며, 어디서 데이터를 가져오는 것일까? 데이터베이스? 로컬 스토리지? 플로피 디스크?
반면에 fetchUserSettings()와 같은 이름은 훨씬 더 많은 정보를 담고 있다. 우리가 가져오는 데이터는 사용자의 설정이며 API에서 이를 가져오는 것이라고 알 수 있다.
하지만 우리가 담아야 할 정보가 너무 많다면? 결국 이름 짓기가 어려운 이유는 의미를 전달하고 작동 방식을 설명해야 하고, 코드의 의도와 부작용을 설명해야 하며, 그것만으로는 부족하다면 가능한 한 짧아야 하는 등 여러 가지 일을 한꺼번에 처리해야 하기 때문이다. 설명하고자 하는 것이 다양한 기능을 수행하는 경우 직관적인 이름을 찾는 것은 정말 어려운 일이 될 수 있다.
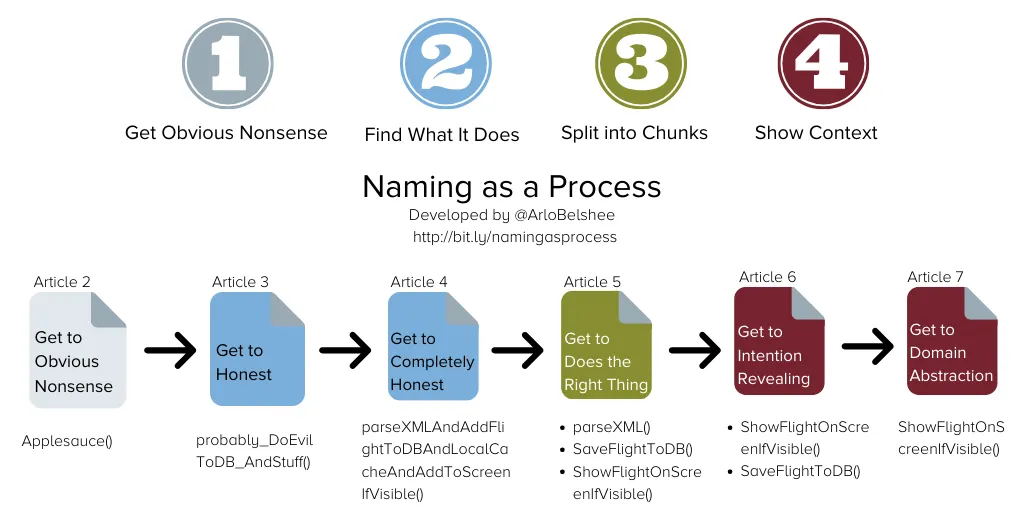
함수, 컴포넌트, 클래스, 모듈 또는 전체 시스템에 적합한 이름을 찾는 데 어려움을 겪고 있는 경우, 이름을 4단계 과정으로 생각하라는 Arlo Belshee의 조언을 따르는 것이 도움이 될 수 있다.
1.
정확한 이름 짓기: 본인이 생각하기에 현재 코드에 대한 이해를 설명하는 가장 정확한 이름을 찾는다. ex) Applesauce()
2.
코드가 하는 일 찾기: 코드가 하는 모든 일을 설명하면, 이름이 길어지지만 정확한 이름이 될 수 있다. ex) parseXMLAndAddFlightToDBAndLocalCacheAndAddToScreenIfVisible()
3.
청크로 나누기: 한 번에 한 가지 일만 처리할 수 있도록 코드를 쪼갠다.
•
parseXML
•
saveFlightToDB
•
showFlightOnScreenIfVisible
4.
컨텍스트 표시: 코드의 의도를 드러내고 도메인 추상화를 찾는다. ex) showFlightOnScreenIfVisible
4번의 말이 좀 어려울 수 있는데 parseXML, saveFlightToDB와 같이 파싱, DB 레벨의 로직은 코드를 사용하는 사용자는 몰라도 되는 로직이다. 그러니 사용자가 알아야하는 컨텍스트의 인터페이스만 드러내는 것으로 이해할 수 있다.
예시: ChatMessageSender
채팅 시스템 코드 중 일부이다. ChatMessageSender는 채팅 메시지를 보내는 컴포넌트라는 것을 알 수 있지만 실제로는 메시지를 보낼 때의 기능 중 파일 업로드, 텍스트 붙여넣기, 이모지, 드래그 앤 드롭 등 많은 기능들이 포함되어 있다는 것을 알 수 있다.
const ChatMessageSender = (props: ChatMessageSenderProps) => {
// ...
const onFileUpload = (event: ChangeEvent<HTMLInputElement>) => {
// ...
};
const onPaste = (event: ClipboardEvent<HTMLInputElement>) => {
// ...
};
const sendFileMessageDirectly = (fileList: File[]) => {
// ...
};
const validateFiles = (filesToUpload: File[]): File[] => {
// ...
};
const onDeleteFile = (name: string) => {
// ...
};
const handleEmojiClick = (emoji: EmojiClickData) => {
// ...
};
const onDrop = (event: DragEvent<HTMLInputElement>) => {
// ...
};
TypeScript
복사
그렇다면 Arlo의 조언에 따라보면, 아래와 같이 코드를 나눌 수 있다.
1.
정확한 이름 짓기: ChatMessageSender
2.
코드가 하는 일 찾기: HandleFileUploadAndEmojiInsertionAndDragDrop
3.
청크로 나누기
•
useFileHandler
•
useEmojiHandler
•
handleDragDrop
4.
컨텍스트 표시: 이 컴포넌트는 채팅 도메인에 어울리는 용어를 사용할 수 있다:
•
ChatInputManager: 채팅 컨텍스트에서 다양한 입력 관련 작업을 관리한다는 것을 암시한다.
•
ChatInteractionHandler: 채팅 내에서 다양한 유형의 사용자 상호작용을 처리한다는 것을 나타낸다.
•
ChatMessageSender: 채팅에서 메시지를 보낼 때와 관련된 작업을 포함한다는 것을 나타낸다.
Use Familiar Patterns
싱글톤, 옵저버, 팩토리 등과 같은 고전적인 디자인 패턴을 사용하면 복잡한 동작에 대해 이야기할 수 있는 공통적인 맥락을 제공한다는 것이다.
예를 들어 코드베이스를 탐색하다가 Pub/Sub 패턴을 사용하는 코드를 발견했다면, 그 코드 주변 코드에 대한 여러 가지 사항을 바로 이해할 수 있다. 게시자와 구독자가 어딘가에 있을 것이고, 그들 사이에 일종의 메시지 브로커가 있을 수 있으며, 이들은 모두 이벤트를 보내 서로 대화할 것이라는 점을 알 수 있다.
포탈 게임 유저가 포탈이 다른 차원으로 이동하지 않는다는 것을 이해하기 위해 설명서를 읽지 않아도 되는 것처럼, 어떤 패턴이 우리에게 익숙하면 그 작동 방식을 이해하기 위해 설명서나 README 파일을 읽을 필요가 없다.
고전적인 OOP 패턴을 사용하지 않더라도, 자체 코드베이스 내에서 일반적으로 사용되는 패턴을 고수함으로써 이 원칙을 활용할 수 있다.
‘익숙함’이라는 키워드가 상당히 중요한데, 많이 본 코드일 수록 우리는 더욱 더 빨리 직관적으로 그 코드의 의미를 파악할 수 있기 때문이다.
users.sort((a, b) => a.age - b.age)
TypeScript
복사
예를 들어 , 이 코드가 users를 가장 어린 사람부터 오름차순 정렬하고 있다는 것을 알 수 있다. 이 패턴은 우리가 이전부터 수없이 많이 보았기 때문이다.
이는 팀 안에서 자주 사용되는 패턴에도 적용된다. 예를 들어, ‘Maybe Operation’은 비동기 조건에 따라 작업을 수행할 수도 있고 수행하지 않을 수도 있는 함수이다(예: API 호출을 통한 사용자 권한 확인). 따라서 예를 들어 maybeSendEmail()이라는 함수가 보이면 즉시 몇 가지 사항을 알 수 있다.
1.
이 함수를 호출한 결과, 이메일이 전송될 수도 있고 전송되지 않을 수도 있다.
2.
이 함수는 비동기식이며 Promise를 반환한다.
3.
Promise는 작업이 발생했는지 여부에 따라 참 또는 거짓으로 확인된다.
이 원칙의 장점은 패턴이 꼭 좋은 것일 필요도 없다는 점이다. 우리에게 익숙한 패턴이라면 이 원칙을 고수하면 코드를 훨씬 더 직관적으로 만들 수 있다.
이러한 패턴은 특정 기술 스택을 사용함으로써 익숙한 코드로 굳어질 수 있다. 예를 들어 우리 회사는 apollo graphql client를 사용하고 있는데, graphql subscription을 사용하면 초기 상태를 가져오는 query가 있을 것이고, 서버로부터 이벤트가 발생할 때마다 데이터를 가져오는 subscription 코드, 그리고 UI 상태를 update 하는 코드가 있을 것이라는 것을 파악할 수 있다.
또한, 아토믹 디자인 패턴을 사용하면 어떤 컴포넌트가 재사용 가능한지 알 수 있다. 우리 회사에서는 molecules, recipes, screens, snowflakes로 컴포넌트를 분리하고 있는데 molecules, recipes에 있는 컴포넌트의 경우 재사용이 가능한 컴포넌트임을 알 수 있다.
즉, 네이밍 컨벤션이든, 린트와 포맷터를 사용한 코드 컨벤션이든, 익숙한 디자인 패턴을 사용하든, 특정 기술 스택을 통한 결과이든, 서비스 코드 내에서 반복되서 나타나는 익숙한 코드가 있고 모두가 합의한 결과라면 그것을 따르는 것이 직관적인 프로그래밍에 도움이 될 수 있다.
그래서 새로운 기술 스택, 새로운 컨벤션을 사용하자고 하는 것은 의미있는 도전이 될 수 있지만 오히려 기존 코드를 레거시로 만들고 휴리스틱하고 직관적인 프로그래밍에서 조금 더 생각을 요하는 복잡한 코드로 만드는 작업이 될 수도 있다. 새롭고 좋은 기술과 컨벤션을 도입하는 것은 나쁘지 않지만 이러한 ‘익숙함’에 대해 팀원들과 합의하는 과정이 꼭 필요할 것이다.
Represent Logic As Data
에릭 노먼드(Eric Normand)는 Grokking Simplicity에서 함수형 프로그래머가 코드를 항상 Action, Calculations, Data의 세 가지 범주로 분류하는 방법에 대해 이야기한다.
1.
Action: 액션은 호출되는 시기 또는 호출 횟수에 따라 달라진다. ex) sendEmail(), getCurrentTime()
2.
Calculations: 계산은 입력에서 출력까지의 계산이며, 언제 또는 몇 번 호출되든 항상 동일하게 작동한다. ex) sum()
3.
Data: 데이터는 이벤트에 대한 기록일 뿐이다.
일반적으로 Data는 Calculations보다 다루기 쉽고, Calculations은 Action보다 다루기 쉽기 때문에 이 구분이 중요하다. Data는 Logic보다 직관적이고 조작하기 쉬우므로 무언가를 Data로 표현할 수 있는 방법을 찾을 수 있다면 그렇게 해야 한다.
예를 들면 자바스크립트에서 Switch 문을 객체 리터럴로 대체할 수 있다. 코드의 데이터와 규칙이 깊이 얽혀 있는 경우와 같이 더 복잡한 사용 사례에도 이 원리를 사용할 수 있다. 로직이 너무 복잡하면 데이터로 대체하는 대신, 로직을 캡슐화하고 간단한 데이터 구조를 통해 그 규칙을 노출할 수 있다.
예시 코드.
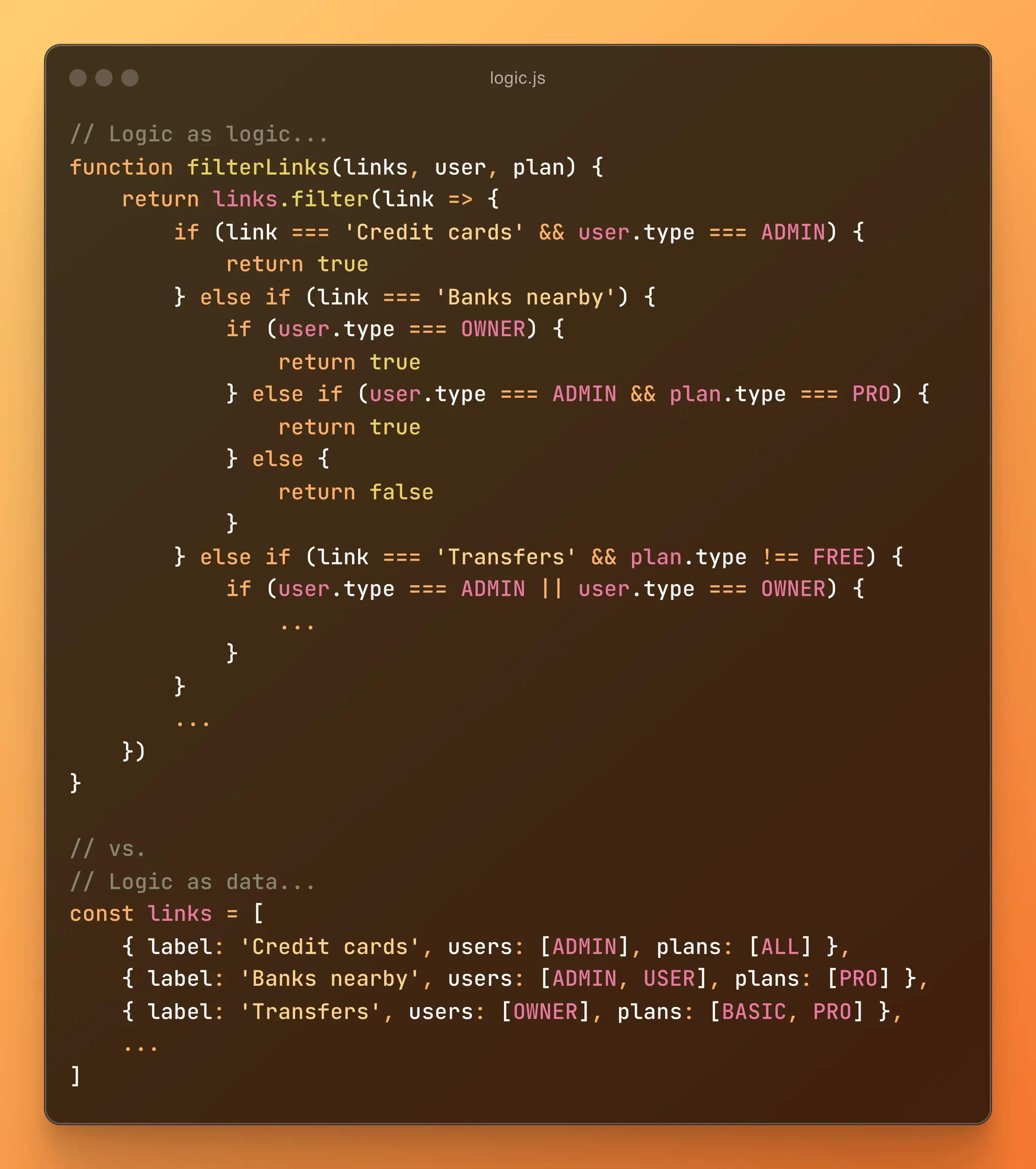
좋은 이름을 선택하는 것과 마찬가지로, 데이터를 표현하는 좋은 방법을 선택하면 코드를 더 직관적으로 만들 수 있을 뿐만 아니라 일반적으로 작업하기가 수월해진다.

직관적인 프로그래밍에 대한 토스 프론트엔드 github discussion 글이다.
조건부 렌더링을 SwitchCase 컴포넌트나 IF 컴포넌트와 같이 컴포넌트를 사용해 나타내는 것이 과연 직관적인 걸까? 라는 질문을 한다.
별표.. ️
️
️같은 컴포넌트를 사용하면 JavaScript에서 Short-circuiting이 보장되지 않아요. 그래서 TypeScript에서 그 하위의 children에서 타입이 좁혀지지 않아서 타입 안전함을 포기하게 돼요. (short-circuit이란? 논리 연산을 나타내기 위해 사용하는 부호 ex. &&, ||)
'컴포넌트 사용'과 '선언적인 코드'는 서로 관계가 없다고 생각합니다. 반복되는 UI 렌더링 로직을 잘 추상화하여 선언적인 형태의 컴포넌트로 만들어서 사용할 때, 선언적인 코드가 되는 것이죠.
주석은 이해하기 어려운 개념을 이해하기 쉬운 개념으로 바꿔주지만, 직관적인 코드는 한 단계 더 나아가 코드를 즉각적으로 이해할 수 있게 해준다.
소프트웨어 복잡성은 시스템을 변경하기 어렵게 만들거나 이해하기 어렵게 만드는 모든 것을 의미한다. 따라서 코드를 더 직관적으로 만들면 단순히 코멘트를 읽는 데 걸리는 몇 초를 절약하는 것뿐만 아니라 복잡성을 직접적으로 해결하는 단초가 될 수 있다.
