_(1).jpeg&blockId=0e552736-74f0-4f5a-89e1-328d4931ca7c)


이전 장


3장에서 B 트리 내용이 남았는데 그날 스터디 참석 못함. 채워넣어야 함
OLTP, OLAP
•
OLTP(transaction processing): 트랜잭션 처리
•
OLAP(analysis processing): 데이터 분석 처리
데이터베이스 웨어하우징(Database Warehousing)
OLTP 데이터베이스는 어플리케이션을 사용하는 유저들이 사용한다.
반면 OLAP 데이터베이스는 데이터를 통해 기업 비즈니스를 분석하는 비즈니스 분석가들이 사용한다.
OLAP는 보통 한꺼번에 많은 데이터를 조회하기 때문에 DB 조회 시 가는 부담이 크다. 때문에 분석용으로 DB를 조회할 때는 유저들이 접근하는 DB를 사용하지 못하도록 DBA가 DB를 복제하여 읽기용 DB를 제공한다.
분석용 DB를 제공할 때 기존 DB에서 ‘데이터 추출(extract) - 분석하기 쉽도록 스키마 변환(transform) - 적재(load)’라는 ETL 과정을 거친다. 이 과정을 거친 DB를 데이터베이스 웨어하우스라고 한다.
스키마 변환
1.
별 모양 스키마, 눈꽃 모양 스키마
ETL 과정 중 분석하기 쉽도록 스키마 변환을 하는 과정을 살펴보겠다. 분석용으로 적절한 스키마의 모양은 ‘별'과 ‘눈꽃'이 있다. 둘이 완전히 다른 스키마라기 보다는 눈꽃 모양 스키마가 별 모양 스키마보다 더 많은 깊이로 테이블이 엮여 있다고 생각하면 된다. 이해가 안되면 일단 계속 읽기 ㄱㄱ.
그 전에 알아둘 용어가 있는데 fact table(사실 테이블)과 dimensional table(차원 테이블)이다. 팩트 테이블은 별 모양, 눈꽃 모양의 가장 가운데에 위치한 테이블이다. 차원 테이블은 팩트 테이블이 참조하는 테이블이다. 차원 테이블은 fact에 대한 육하원칙을 나타낸다.
뉴스를 생각하면 쉽다.
2022년 2월 22일 우리나라와 중국 오버워치 프로게이머들이 A방송국에서 오버워치 경쟁전을 벌였다.
2022년 2월 22일 홍진호와 임요환이 A방송국에서 스타크래프트 경쟁전을 벌였다.
2022년 2월 23일 페이커와 쇼메이커가 B방송국에서 롤 경쟁전을 벌였다.
이런 게임 뉴스들이 있다고 해보자. 각 뉴스를 하나의 row라고 하면 각 row는 하나의 팩트를 나타낸다. 그리고 이 팩트들은 각각 ‘누가(Who), 언제(When), 어디서(Where), 왜(Why), 무엇을(What), 어떻게(How)’ 라는 데이터들로 나눌 수 있다.
언제 | 누가 | 어디서 | ... |
2022.02.22 | 우리나라/중국 | A방송국 | |
2022.02.22 | 홍진호/임요환 | A방송국 | |
2022.02.23 | 페이커/쇼메이커 | B방송국 |
이때 when은 dim_date라는 날짜를 나타내는 차원 테이블, who는 dim_person이라는 차원테이블, ... 이렇게 각각 다른 테이블로 나뉜다. 팩트 테이블은 차원 테이블들을 참조한다. 아래 그림과 같이 팩트 테이블이 각각 차원 테이블과 연결된 모습이 마치 별과 같아 별 모양 스키마라고 한다.
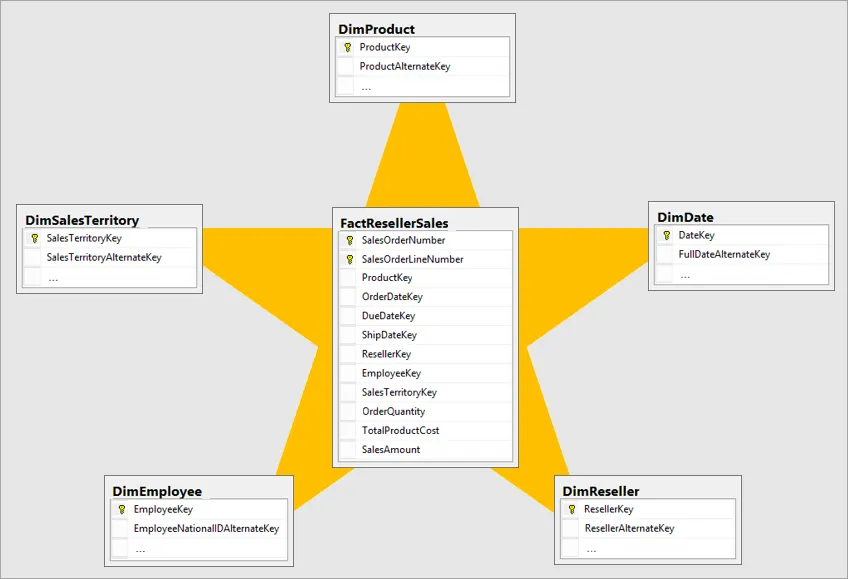
눈꽃 모양 스키마는 차원 테이블에서 더 하위의 차원 테이블로 나뉘어지는데, 한 꼭지점에서 다시 여러 갈래로 나뉘는 모습이 눈꽃과 비슷하다.
왜 이렇게 차원을 나누는 것일까?
where 조건문에서 컬럼을 수식(함수)로 감싸면 해당 컬럼의 인덱스를 못쓰게 된다고 한다. 그러나 컬럼을 차원 테이블로 나눠놓으면 해당 table에 인덱스를 걸어 더 빠르게 조회가 가능하다.
2.
칼럼 지향 저장소
왜 사용하는가? 성능, 용량 두 가지 장점이 있다.
성능: 분석용으로 데이터 조회할 때 필요한 컬럼들로만 필터링하기 위해서
기업마다 다르겠지만 팩트 테이블은 보통 컬럼의 양이 100개를 넘는다고 한다. 문제는 분석을 위해 데이터를 조회할 때 실제 필요한 컬럼은 몇 개 밖에 안된다는 것이다. 대부분의 OLTP DB는 row를 중심으로 데이터를 조회한다. row 중심의 DB를 조회할 때, 필요한 컬럼 외에 수많은 컬럼이 포함된 로우까지 메모리에 적재하여 필터링해야 하므로 시간이 오래 걸릴 수 있다.
반면, 컬럼 지향 저장소는 데이터를 컬럼 중심으로 저장한다(row의 순서가 변하지 않는다는 가정 하에). 그럼 필요한 컬럼들만 뽑아서 데이터를 조회할 수 있다.
예를 들어 언제, 누가라는 데이터만 조회한다면 두 컬럼만 사용한다. ‘언제’에 필터링이 걸려있다면 조건에 충족하는 값의 인덱스를 뽑아 ‘누가'라는 컬럼에서도 같은 인덱스의 값을 뽑으면 된다. 이는 row의 순서가 같기 때문에 가능하다.
용량: run length 부호화를 통해 여러 데이터를 하나로 압축할 수 있다.
age라는 컬럼에 17, 20, 22, 27, 29 등이 있다고 하자.
age: 17, 20, 22, 22, 22, 27, 29, 29 이라고 할 때 이를 비트맵으로 변환하면 다음과 같다.
age | 17 | 20 | 22 | 22 | 22 | 27 | 29 | 29 |
17 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
20 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
22 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 |
27 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
29 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
run-length 부호화로 (데이터에서 같은 값이 연속해서 나타나는 것을 그 개수와 반복되는 값만으로 표현하는 방법 - 위키) 압축해보면... 이런 식으로 bit를 더 짧게 변환하여 표현할 수 있다.
17은 1이 1개, 나머지 0 7개 → 1
20은 0 1개, 1 1개, 나머지 6개 → 1 1
여기서 where age = 22 or 29 라고 하면 or 연산은 둘 중 하나만 1이어도 참이므로 두 비트맵을 OR 연산했을 때 0 0 1 1 1 0 1 1 이 된다. 그럼 row 중 0 0 1 1 1 0 0 0 을 만족하거나 0 0 0 0 0 0 1 1 을 만족하는 row를 찾아 반환하게 될 것이다.
references
•
책 데이터중심어플리케이션설계 3장
