_(1).jpeg&blockId=0e552736-74f0-4f5a-89e1-328d4931ca7c)

왜 배우는가
개발자는 데이터를 추상화하여 하나의 계층 위에 또 하나의 데이터 계층을 만든다. 데이터를 추상화하여 데이터 계층을 쌓아나간다. 각 계층의 데이터 모델은 하위 계층의 복잡성을 숨긴다.
어플리케이션이 어떤 데이터를 다루느냐에 따라 어떤 데이터 모델을 선택할지 결정된다. 데이터 모델은 소프트웨어가 할 수 있는 일과 없는 일에 영향을 주므로 어플리케이션에 적합한 모델을 찾는 것이 중요하다.
데이터 모델의 종류
1.
계층 모델(1960년대~)
•
1970년대 비즈니스 데이터 처리를 위해 가장 많이 사용한 DB는 IMS. IMS가 사용한 데이터 모델이 계층 모델.
•
문서 DB에서 사용하는 JSON 모델과 비슷하다.
•
문서 DB처럼 일대다 관계는 잘 동작하지만 다대다 관계 표현은 어렵고 조인은 지원하지 않았다.
•
계층 모델의 한계를 극복하기 위해 관계형 모델(이후 SQL), 네트워크 모델이 등장했다.
◦
네트워크 모델은 현재 잊혀졌지만 관계형 모델과 네트워크 모델을 살펴보는 이유는 이 두 모델이 해결하려는 문제가 오늘날의 기술과도 연관성이 많기 때문이다.
2.
네트워크 모델
•
코다실이라는 의원회에서 표준화
•
계층 모델을 일반화: 계층 모델의 트리 구조에서 모든 레코드는 정확하게 하나의 부모가 있다.
•
네트워크 모델에서는 레코드는 다중 부모를 가질 수 있다.
•
따라서 다대일, 다대다 관계를 쉽게 모델링 할 수 있다.
3.
관계형 모델(1960년대~)
•
1970,80년대에는 네트워크 모델, 계층 모델이 우세했으나 결국에는 관계형 모델이 승리
•
데이터는 관계로 구성된다
•
저장, 질의할 때는 간단한 인터페이스를 사용하게 하고 그 뒤로 복잡한 구현 사항을 숨긴다.
•
트랜잭션 처리, 일괄 처리
•
조인, 다대일, 다대다 관계를 더 잘 지원
4.
문서 모델(2010년대~)
•
스키마 유연성: 관계형 데이터베이스의 ‘스키마'가 주는 제한에서 벗어나 동적이고 자유로운 데이터 모델의 필요성으로 등장
•
지역성: 모든 정보가 한 문서에 저장되어 있다. 이 지역성 때문에 관계형 모델모다 성능이 더 좋다.
•
뛰어난 확장성으로 대규모 데이터셋 및 쓰기 처리량 소화 가능
•
문서 모델은 조인에 대한 지원이 약하기 때문에 만약 다대일 관계(ex. 많은 사람들이 한 직장에서 일한다)의 데이터가 필요하다면 다중 질의를 만들어서 조인을 흉내내야 한다. 반면 일대다 관계에 대해서는 조인이 필요하지 않다.
5.
그래프 모델
•
다대다 관계가 매우 일반적인 경우에 사용
•
문서 모델과의 공통점: 스키마리스한 특성때문에 확장성이 좋다. 변경사항을 쉽게 적용할 수 있는 유연성이 있다.
•
속성 그래프, 트리플 저장소 모델로 나뉜다
◦
트리플 저장소
▪
시맨틱 웹: 사람이 읽을 수 있는 정보로 구성된 웹 사이트를 컴퓨터가 읽을 수 있는 데이터로도 정보를 구성.
▪
데이터 사일로(데이터 간 장벽)를 없애고 비슷한 서비스 간 데이터를 상호 운용하기 쉽게(웹의 창시 목적인 데이터 공유와 생산을 용이하게 하기 위해서) 하기 위해 RDF(자원 기술 프레임워크)를 사용해 서로 다른 웹 사이트가 일관된 형식으로 데이터를 게시하는 방법을 제안한다
▪
트리플 저장소의 터틀 언어는 RDF로 표현된 데이터를 사람이 읽을 수 있는 형태로 보여준다. 단적인 예로는 URI가 있다.
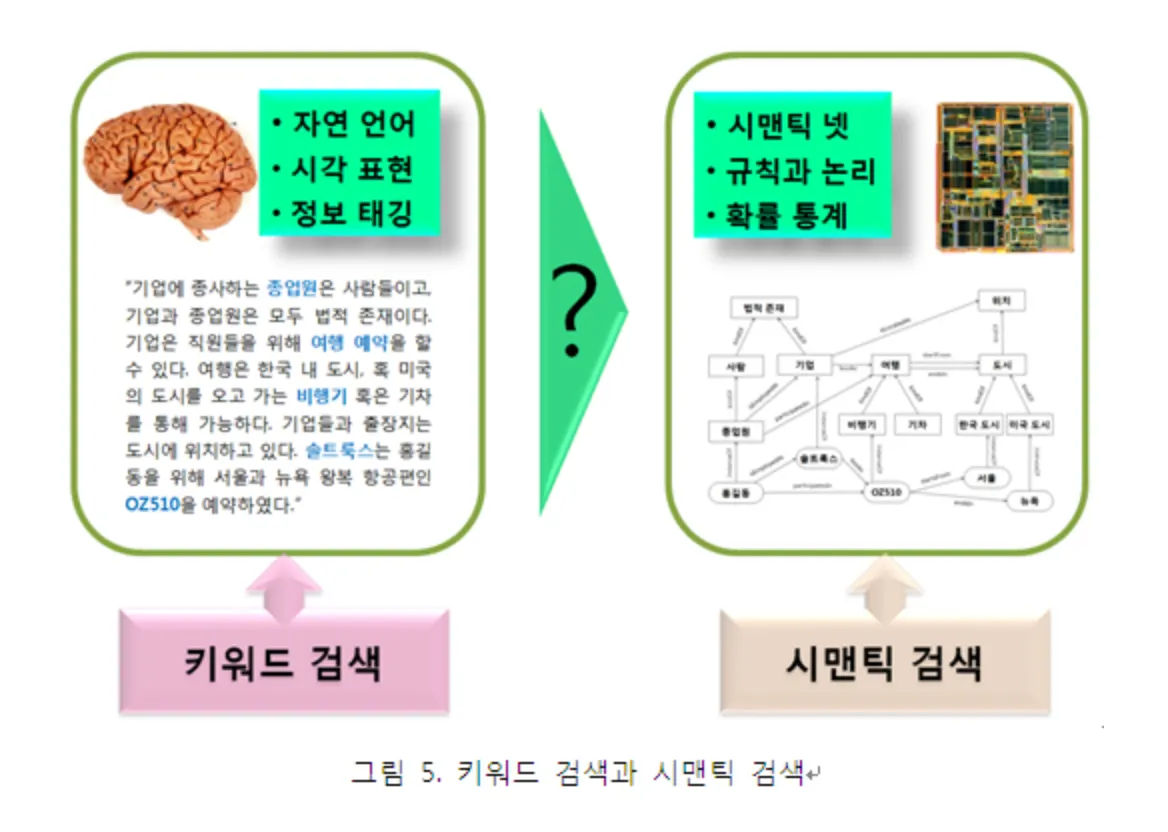
출처: dataonair

기존의 키워드 기반 검색과 시맨틱 검색의 차이를 보이고 있다. 키워드 기반 검색은 키워드(토큰)를 텍스트로부터 분리(형태소 분석)하여 이를 역파일 형태로 인덱스에 저장하게 된다.
반면에 시맨틱 웹 검색은 웹 상에 이미 존재하는 RDF 메타데이터 그래프를 색인하는 것이고, 넓은 의미의 의미기반 검색은 텍스트, 이미지, 동영상 등의 다양한 형태의 문서에서 어떤 방법이던 의미 메타데이터를 자동 추출하여 시맨틱 그래프를 자동 구성하는 과정을 포함한다.
구글의 페이지 랭크는 2012년도부터 시맨틱 웹 검색을 사용해 재현율을 유지하며 상위 랭크의 정확률을 높여 큰 성공을 하였으며, 네이버의 지식인은 집단지성과 손맛을 통해 정확률을 높여 성공한 사례라 하겠다.
시맨틱 검색은 시맨틱 웹의 비전과 유사하게, 기계가 방대한 검색 결과를 인간 대신 읽고 분석하여 정리해 주기를 바라는, 그리고 보다 정확한 답 혹은 가장 관련성 깊은 정보를 빠르게 찾게 하겠다는 목표를 가지고 있다.
- dataonair 참고
•
그래프 DB와 네트워크 모델의 차이
◦
네트워크 모델에는 스키마가 있지만 그래프 모델에는 이런 제한이 없다. 변경사항을 쉽게 적용할 수 있는 유연성이 있다.
◦
네트워크 모델은 데이터를 조회하기 위해 레코드 접근 경로를 하나하나 탐색해봐야 한다. 그래프 모델은 고유한 ID로 직접 참조하거나 색인을 사용해 레코드를 더 빠르게 찾을 수 있다.
어떤 데이터 모델을 사용할까
•
애플리케이션이 다루는 데이터가 문서와 비슷한 구조 (일대다 관계 트리)이거나 레코드 간 관계가 없다면 문서 모델 사용
•
상호 연결이 많은 데이터의 경우 관계형 모델 또는 그래프 모델 사용
references
•
책 데이터중심어플리케이션설계
